The launch of the guide in Norway

Norwegian Ombudsman for Equality and Anti-Discrimination launches guide to built-in protection against AI discrimination


Published in Ethical AI Resources November 14, 2023
The Norwegian Ombudsman for Equality and Anti-Discrimination (Listening or Discrimination Budget, LDO) has just launched a guide to uncovering and preventing discrimination in the development and use of artificial intelligence. In Norway, citizens have strong legal protections to protect themselves against discrimination and to ensure equality. In this article, I'll try to briefly review the launch and some key points from the guide. Please note that the original guide was published in Norwegian, but I will do my best to provide you with a summary in English. I also translate part of the text and illustrations.
The launch of the guide in Norway
The launch was attended by the Norwegian Minister of Digitization and Governance, Karianne Tung .

The guide was launched on November 8, 2023.

The guide was largely written by Kathinka Theodore Aakenes Vik , senior advisor at LDO.

The press release states that:
“The risk of discrimination is among the biggest risks when using artificial intelligence to make decisions about individuals — for example, who should receive social benefits, health care or credit loans. While the use of AI is increasing, studies show that there is little awareness and competence about discrimination in both the public and private sectors. The Ombudsman for Equality and Discrimination is therefore launching a guide on how development teams reduce the risk of discrimination in AI systems be able to estimate.”
Background for the guide
Over the past decade, the media have reported scandals where algorithms and machine learning models have led to discrimination, often because the technology has not been reviewed thoroughly enough. Two examples of this are facial recognition that does not work adequately with dark-skinned people, and algorithms used to detect fraud that incorrectly identifies people with an immigrant background.
The examples show that it is not enough to take into account the risk of discrimination when developing and using this technology. Discrimination must be systematically prevented and measured. Measures to prevent discrimination and promote equality must be incorporated into all phases of the development of a machine learning system (ML), from planning to using the technology. We call this built-in protection against discrimination .
The full guide (in Norwegian) you can find here:
Innbygd discriminatory springs
A veil for preventing and preventing discrimination and the use and use of artificial intelligence
www.ldo.no
So who is this guide for?
Target group: those responsible for developing, purchasing and using machine learning systems where use implies that the systems can have an impact on people's rights and obligations .
What is it based on?
The guide is inspired, among other things, by “Nondiscrimination by design,” Fundamental Rights and Algorithm Impact Assessment (FRAIA) country “Promoting equity in the use of Artificial Intelligence — an assessment framework for non-discriminatory AI” .
Why is it crucial to consider?
Norwegian law prohibits discrimination in all areas of society. The ban is based on the principle of equality and non-discrimination, which is enshrined in article 98 of the Constitution. This principle is also at the heart of the European Human Rights Convention (ECHR) and various other human rights treaties. In addition, there are many overlapping opportunities for discrimination that require careful navigation.
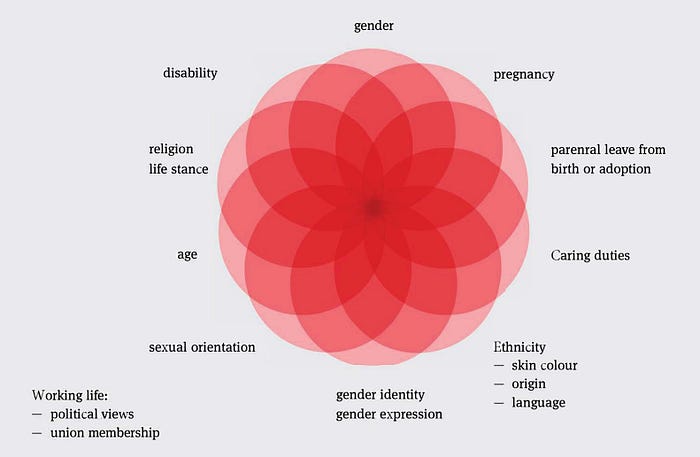
To help people who work with the development, purchase, or use of machine learning systems, the guide covers different phases.
The guide is structured in phases with relevant discrimination challenges and case examples.
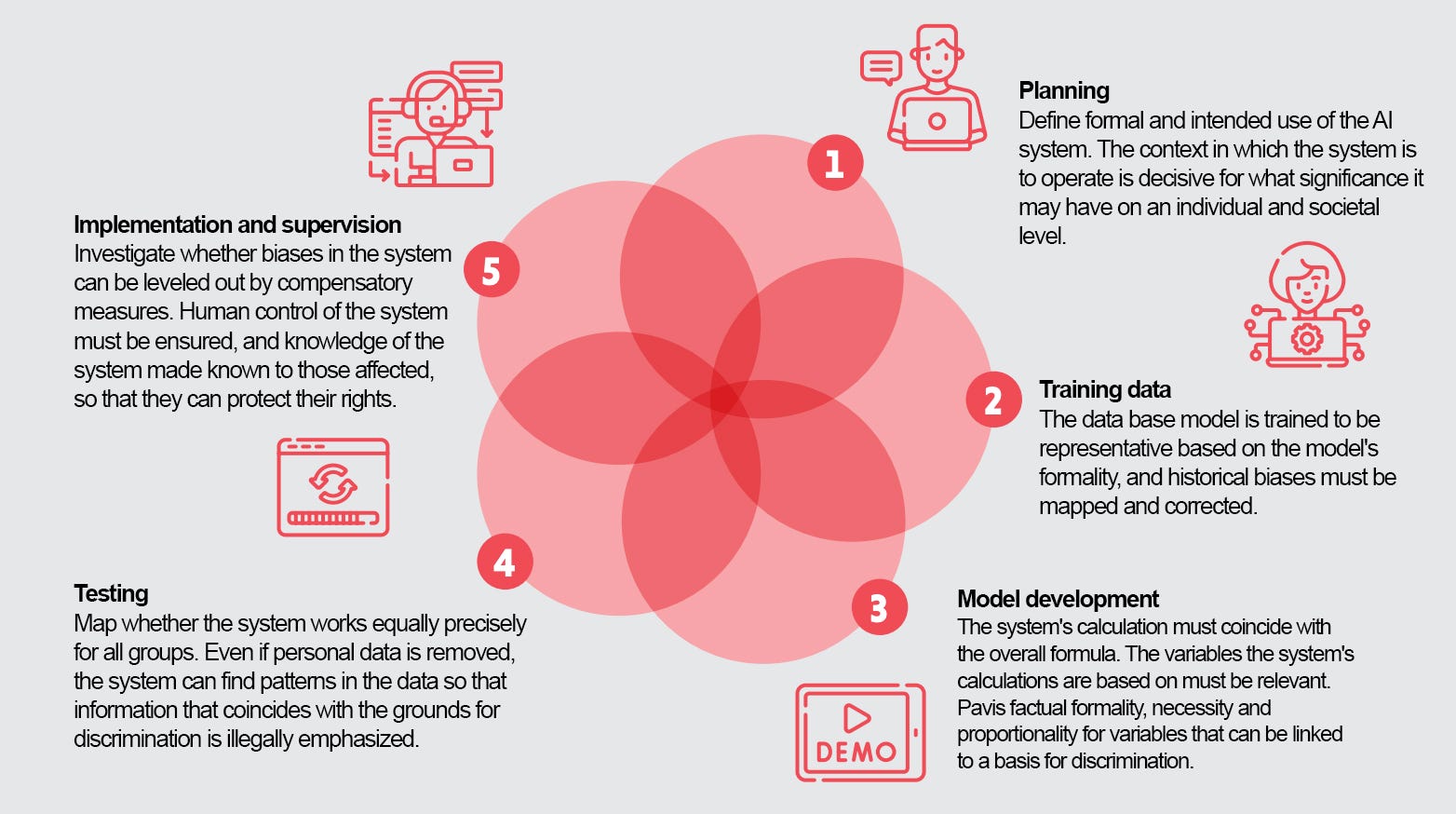
1. Planning
The first phase is about highlighting the problem that the system is supposed to solve, defining what the purpose is, the success criteria and what social and political consequences the use can have from the perspective of equality and discrimination.
Relevant discrimination challenges
The intended use of the ML model may be decisive for the risk of discrimination. If the ML model was developed to calculate the starry sky and that of planet localization, this guide is probably not relevant. In contrast, if the ML model is developed to predict which citizens who will receive social assistance benefits, the issue of discrimination applies. Furthermore, within the models that can have an impact on people's rights and obligations, there is a difference between ML systems that are used for:
- Audit objective: The system is intended to control people and can be used to punish people. The system can discriminate by controlling certain parts of the population disproportionately extensively or more deeply than others.
- Allocation goal: The system aims to provide citizens with a better and correct service. Such systems can discriminate if they are less accurate for certain groups. This can happen, for example, within the healthcare sector, in the sense that certain groups of people do not receive equivalent public services that they can claim.
In the guide, they ask a series of questions.
Purpose of the model :
- What is the intended use of the system? In what context should it function?
- How autonomous is the system?
- Which groups of people stand out and why?
- Are representatives of these groups of people involved and heard during the planning and design of the system?
The effect of the model:
- What significance can the system have for certain people?
- Is it used (as part of a process) to determine the legal status of individuals?
Audit objective: Control of people? Like predicting possible future behavior? - Who is affected by the model? - Will some groups of people be additionally exposed to discrimination during inspections?
Purpose of the prize : Improving (access to) services for people? -Which groups of people will be affected by the model?
- What significance can the system have on a social level?
- Can the system improve previous practices in preventing discrimination or other types of errors?
Success criteria : How should success be measured in terms of efficiency or increased precision?
What do the success criteria mean for different groups of people?
In this section, the guide also provides specific examples from a Norwegian context.
2. Training data
This phase involves the correct collection, processing and use of data. Training a machine learning model requires large amounts of data and, in the background of this data, the machine learns to recognize patterns. The data will determine which connections the system detects and which predictions the system provides
Current issues that need to be discussed
- Data needs : Collection - What data is needed to achieve the goal with the model? -Does the company have internal access to the data, or does it have to be obtained from external sources?
- Data quality : Map the database - Is the database representative in line with the purpose of the model? Are some groups over- or under-represented? -What can be the result of failure representation? -Can some groups of people have different data patterns in relation to what the model calculates? Take the ground of discrimination as a starting point.
3. Model development
This phase is about how the model will operationalize the purpose of the model. Decisive in this phase is that what the model calculates matches what you want to achieve .
Relevant discrimination challenges
A typical source of discrimination is that the value calculated by the model does not match its actual purpose. This can be called measurement bias. The challenge can occur when the purpose of the system is not immediately observable or measurable. The data and variables used in the system thus simplify the overall goal, and there may be a risk of more weaknesses in the system as a whole, including a risk of discrimination.
Current issues that need to be discussed
- What does the model need to calculate?
- How does the calculation correlate with the overall goal
- On which variables is the calculation of the model based and why are they relevant?
- If the variables can be linked to a ground of discrimination — can the actual purpose, necessity and proportionality be detected?
- Is one model sufficient or do you need to develop more models that are comparable with regard to possible prejudice and justice?
4. Test the system
This phase is about how to test the system before it is implemented. Because testing must be limited in scope and time, it is essential that the system is tested for relevant risks.
Relevant discrimination challenges
Even if the system does not use personal data that is a basis for discrimination, there is a risk that other, apparently neutral information, will reveal links that coincide with the grounds for discrimination. The reason for this is that machine learning models are often superior in exposing relationships, but have a limited ability to distinguish between causality and correlations .
Research shows that it can be useful to keep personal data that is directly related to the grounds of discrimination, so that we can test the system and see if different groups of people are doing worse than others.
A particular challenge to consider when testing the system, the aforementioned phenomenon, is compound discrimination.
If the system is tested for discrimination at a group level that is completely above it (such as gender), discrimination can be masked more finely — then the group level can be overlooked. The combinations of grounds for discrimination are, as it were, endless (e.g. different age groups, gender, different variants of functional disabilities, different ethnicities).
This shows the importance of knowledge of social conditions and the assumptions from different groups in the context in which the system must function, in order to be able to test the system for possible weaknesses.
Current issues that need to be discussed
Perform system testing:
- How does the model perform against the success criteria defined in phase 1? As such: -How does the system perform in terms of false positive/false negatives for different groups? — compare results for the different groups. -Is there data available to check for discrimination against different groups? -Who is responsible for monitoring the model's performance at these points?
- How are their representatives involved in the testing phase?
Correlations or causality:
Document background for connections
- What are the underlying reasons for the predictions that the system provides?
- Research or linking data can lead to the derivation of personal data that can be linked to grounds of discrimination. -If so, what's the reason for this? -Consider the actual purpose, necessity and proportionality.
5. Implementation
This phase is about how the use of the system is taken into account. The phase assumes that testing the system (phase 4) provides satisfactory results.
Relevant discrimination challenges
If identifying the questions in the previous phases shows that the system risks working worse for certain groups, or treating certain groups more strictly than others, and this cannot be adjusted in the system itself, research should be done whether there is a possibility of offering one alternative treatment that provides equal treatment to the groups concerned. If that ML system is deployed, it is crucial to monitor how the system performs over time. This technology is dynamic and changes based on the experience systems determine the length of time it is put into use. Therefore, a non-discriminatory model can develop discriminatory properties over time.
Current issues that need to be discussed
The addition to the model:
- Can the system's discriminatory calculations be offset in light of relevant groups of people?
Audit :
- How can true human verification of decisions about individual elements of the model be guaranteed?
- How is structural control with the system ensured? As such: - Model controls ensure equally accurate decisions for all groups, and- Control mechanisms to ensure that the model does not systematically process certain groups more rigorously.
Request for information (innsyn) and communication :
- For whom should knowledge of the system and its application be open and available? Identify what information the different stakeholder groups need to ensure the trust society, and what guidelines it sets out for how the information is made available.
- How are those affected by the system represented for their interests? As such: -Necessary insight into how the model works? -What discrimination assessments are being carried out? -Are there any real calls?
Evaluation:
- Define an evaluation strategy (continuous or periodic) and preferably involve external experts and interest groups that can represent stakeholders.
- How would the system have worked with an alternative model, justice definition, or algorithm?
- Based on the evaluation, should the system be further deployed, modified or terminated?
Special thanks for developing the guide
The author thanks Inga Strümke (NTNU), Helga Brøgger (DNV), Robindra Prabhu (NAV), Iris Bore (NAV), Rita Gyland (NAV), Jacob Sjødin (NAV), Professor Dag Elgesem (UiB) and Vera Sofie Borgen Skjetne (BufDir), who provided input in developing guide this.
I hope you found this useful, and it brings you up to date with some of the developments underway in Norway in AI policy and ethics.
This is also part of my personal project #1000daysofAI and you're reading article 519. For 1,000 days, I'm writing one new article about or related to artificial intelligence. For the first 500 days, I wrote an article every day, and now from 500 to 1000 I write at a different pace.
Artificial intelligence AI policy Norway Discrimination Policy
.avif)