De lancering van de gids in Noorwegen

Nieuwe Noorse gids ter voorkoming van AI-discriminatie gelanceerd in samenwerking met de minister van Digitalisering
De Noorse Ombudsman voor Gelijkheid en Antidiscriminatie lanceert een gids voor ingebouwde bescherming tegen AI-discriminatie


Gepubliceerd in Ethische AI-bronnen 14 november 2023
De Noorse Ombudsman voor Gelijkheid en Antidiscriminatie (Likestillings- og diskrimineringsombudet, LDO) heeft zojuist een gids gelanceerd voor het blootleggen en voorkomen van discriminatie bij de ontwikkeling en het gebruik van kunstmatige intelligentie. In Noorwegen hebben burgers sterke wettelijke bescherming om zich te beschermen tegen discriminatie en om gelijkheid te waarborgen. In dit artikel zal ik proberen de lancering en enkele belangrijke punten uit de gids kort te bespreken. Houd er rekening mee dat de originele gids in het Noors is uitgegeven, maar ik zal mijn best doen om u een samenvatting in het Engels te geven. Ook vertaal ik een deel van de tekst en de illustraties.
De lancering van de gids in Noorwegen
De lancering werd bijgewoond door de Noorse minister van Digitalisering en Bestuur, Karianne Tung .

De gids werd gelanceerd op 8 november 2023.

De gids is voor een groot deel geschreven door Kathinka Theodore Aakenes Vik , senior adviseur bij LDO.

Uit het persbericht wordt vermeld dat:
“Het gevaar van discriminatie behoort tot de grootste risico’s wanneer kunstmatige intelligentie wordt gebruikt om beslissingen te nemen over individuen – bijvoorbeeld wie sociale uitkeringen, gezondheidszorg of kredietleningen zou moeten ontvangen. Terwijl het gebruik van AI toeneemt, blijkt uit onderzoeken dat er in zowel de publieke als de private sector weinig bewustzijn en weinig competentie bestaat over discriminatie. De Ombudsman voor Gelijkheid en Discriminatie lanceert daarom een gids over hoe ontwikkelingsteams het risico op discriminatie in AI-systemen kunnen inschatten .”
Achtergrond voor de gids
De afgelopen tien jaar hebben de media melding gemaakt van schandalen waarbij algoritmen en machine learning-modellen tot discriminatie hebben geleid, vaak omdat de technologie niet grondig genoeg is beoordeeld. Twee voorbeelden hiervan zijn gezichtsherkenning die niet adequaat werkt bij mensen met een donkere huidskleur, en algoritmen die worden gebruikt om fraude op te sporen die mensen met een allochtone achtergrond ten onrechte identificeert.
Uit de voorbeelden blijkt dat het niet voldoende is om bij de ontwikkeling en het gebruik van deze technologie rekening te houden met het risico op discriminatie. Discriminatie moet systematisch worden voorkomen en gemeten. Maatregelen om discriminatie te voorkomen en gelijkheid te bevorderen moeten worden ingebouwd in alle ontwikkelingsfasen van een machinaal leersysteem (ML-systeem), van de planning tot het gebruik van de technologie. Wij noemen dit ingebouwde bescherming tegen discriminatie .
De volledige gids (in het Noors) vindt u hier:
Innebygd diskrimineringsvern
Een sluier voor het voorkomen en voorkomen van diskriminering en het gebruik en gebruik van kunstige intelligentie
www.ldo.no
Dus voor wie is deze gids bedoeld?
Doelgroep: degenen die verantwoordelijk zijn voor de ontwikkeling, aanschaf en gebruik van machine learning-systemen waarbij het gebruik impliceert dat de systemen impact kunnen hebben op de rechten en plichten van mensen .
Waar is het op gebaseerd?
De gids is onder meer geïnspireerd op ‘Nondiscrimination by design’, Fundamental Rights and Algorithm Impact Assessment (FRAIA) en ‘Promoting equity in the use of Artificial Intelligence – an assessment framework for non-discriminatory AI’ .
Waarom is het cruciaal om te overwegen?
De Noorse wet verbiedt discriminatie op alle terreinen van de samenleving. Het verbod is gebaseerd op het beginsel van gelijkheid en non-discriminatie, dat is vastgelegd in artikel 98 van de Grondwet. Dit beginsel staat ook centraal in het Europees Mensenrechtenverdrag (EVRM) en diverse andere mensenrechtenverdragen. Bovendien zijn er veel overlappende mogelijkheden voor discriminatie die zorgvuldige navigatie vereisen.
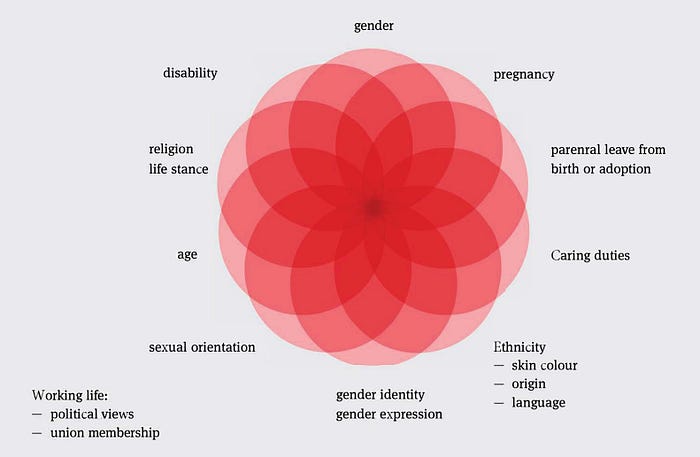
Om mensen te helpen die werken met de ontwikkeling, aanschaf of het gebruik van machine learning-systemen, behandelt de gids verschillende fasen.
De gids is gefaseerd opgebouwd met relevante discriminatie-uitdagingen en casusvoorbeelden.
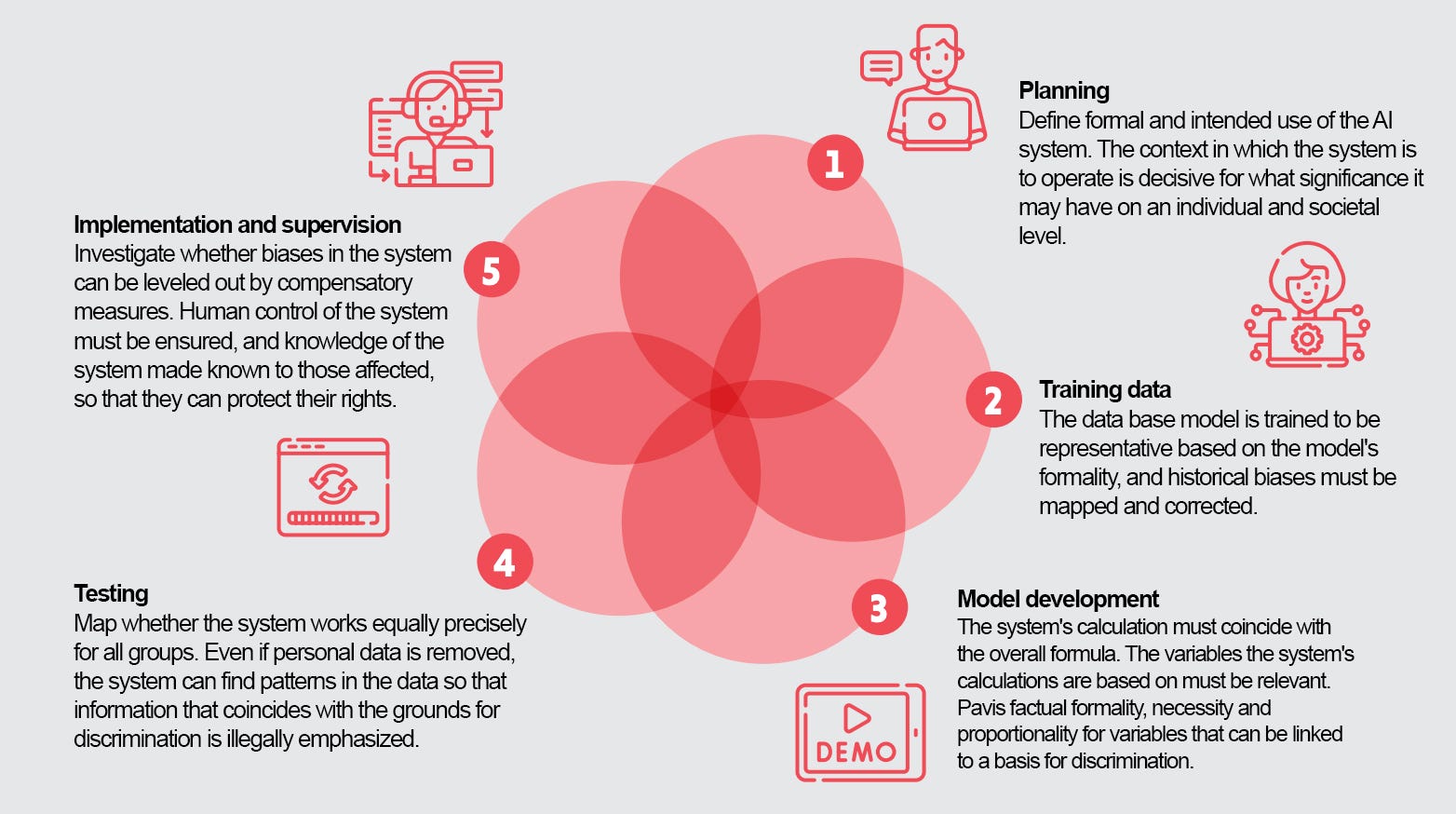
1. Plannen
De eerste fase gaat over het onder de aandacht brengen van het probleem dat het systeem geacht wordt op te lossen, het definiëren van wat het doel is, de succescriteria en welke sociale en politieke gevolgen het gebruik kan hebben vanuit het perspectief van gelijkheid en discriminatie.
Relevante discriminatie-uitdagingen
Het beoogde gebruik van het ML-model kan doorslaggevend zijn voor het risico op discriminatie. Als het ML-model is ontwikkeld om de sterrenhemel en die van de planeetlokalisatie te berekenen, is deze gids waarschijnlijk niet relevant. Als het ML-model wordt ontwikkeld om te voorspellen welke burgers aan wie een bijstandsuitkering wordt toegekend, is de kwestie van discriminatie daarentegen van toepassing. Verder is er binnen de modellen die impact kunnen hebben op de rechten en plichten van mensen een verschil tussen ML-systemen die gebruikt worden voor:
- Controledoel: Het systeem is bedoeld om mensen te controleren en kan worden gebruikt om mensen te bestraffen. Het systeem kan discrimineren door bepaalde delen van de bevolking onevenredig uitgebreid of diepgaander te controleren dan andere.
- Toewijzingsdoel: Het systeem heeft tot doel burgers een betere en correcte dienstverlening te bieden. Dergelijke systemen kunnen discrimineren als ze voor bepaalde groepen minder nauwkeurig werken. Dit kan bijvoorbeeld gebeuren binnen de gezondheidszorgsector, in die zin dat bepaalde groepen mensen geen gelijkwaardige openbare diensten ontvangen waarop zij aanspraak kunnen maken.
In de gids stellen ze een reeks vragen.
Doel van het model :
- Wat is het beoogde gebruik van het systeem? In welke context moet het functioneren?
- In hoeverre is het systeem autonoom?
- Welke groepen mensen onderscheiden zich en waarom?
- Zijn vertegenwoordigers van deze groepen mensen betrokken en gehoord tijdens de planning en het ontwerp van het systeem?
Het effect van het model:
- Welke betekenis kan het systeem voor bepaalde mensen hebben?
- Wordt het gebruikt (als onderdeel van een proces) om de juridische status van individuen te bepalen?
Controledoel: Controle van personen? Zoals het voorspellen van mogelijk toekomstig gedrag?- Wie wordt door het model beïnvloed?- Zullen sommige groepen mensen tijdens inspecties extra worden blootgesteld aan discriminatie?
Doel van de prijs : Verbetering van (toegang tot) diensten voor mensen?-Welke groepen mensen zullen door het model worden beïnvloed?
- Welke betekenis kan het systeem hebben op maatschappelijk niveau?
- Kan het systeem eerdere praktijken verbeteren op het gebied van het voorkomen van discriminatie of andere soorten fouten?
Succescriteria : Hoe moet succes worden gemeten in termen van efficiëntie of verhoogde precisie?
Wat betekenen de succescriteria voor verschillende groepen mensen?
De gids geeft in deze sectie ook specifieke voorbeelden uit een Noorse context.
2. Trainingsgegevens
In deze fase gaat het om het correct verzamelen, verwerken en gebruiken van gegevens. Voor het trainen van een machine learning-model zijn grote hoeveelheden gegevens nodig en op de achtergrond van deze gegevens leert de machine patronen te herkennen. De data zullen bepalend zijn voor welke verbindingen het systeem detecteert en welke voorspellingen het systeem geeft
Actuele kwesties die besproken moeten worden
- Behoefte aan gegevens : Verzameling-Welke gegevens zijn nodig om het doel met het model te bereiken?-Heeft het bedrijf intern toegang tot de gegevens, of moet deze worden verkregen uit externe bronnen?
- Gegevenskwaliteit : Breng de database in kaart-Is de database representatief opgezet in overeenstemming met het doel van het model? Zijn sommige groepen over- of ondervertegenwoordigd?-Wat kan het gevolg zijn van faalrepresentatie?-Kunnen sommige groepen mensen afwijkende gegevenspatronen hebben in relatie tot wat het model berekent? Neem de discriminatiegrond als uitgangspunt.
3. Modelontwikkeling
Deze fase gaat over hoe het model het doel van het model zal operationaliseren. Doorslaggevend in deze fase is dat wat het model berekent overeenkomt met wat je wilt bereiken .
Relevante discriminatie-uitdagingen
Een typische bron van discriminatie is dat de door het model berekende waarde niet overeenkomt met het werkelijke doel ervan. Dit kan meetvertekening worden genoemd. De uitdaging kan zich voordoen als het doel van het systeem niet direct waarneembaar of meetbaar is. De gegevens en variabelen die in het systeem worden gebruikt, vormen dus een vereenvoudiging van het algemene doel, en er kan een risico bestaan op meer zwakke punten in het systeem als geheel, inclusief een risico op discriminatie.
Actuele kwesties die besproken moeten worden
- Wat moet het model berekenen?
- In hoeverre correleert de berekening met het algemene doel
- Op welke variabelen is de berekening van het model gebaseerd en waarom zijn deze relevant?
- Als de variabelen in verband kunnen worden gebracht met een grond voor discriminatie – kunnen het feitelijke doel, de noodzaak en de evenredigheid dan worden opgespoord?
- Is één model voldoende of moet je meer modellen ontwikkelen die vergelijkbaar zijn met betrekking tot eventuele vooroordelen en rechtvaardigheid?
4. Het systeem testen
In deze fase gaat het erom hoe het systeem getest moet worden voordat het geïmplementeerd wordt. Omdat het testen beperkt moet zijn in omvang en tijd, is het essentieel dat het systeem wordt getest op relevante risico's.
Relevante discriminatie-uitdagingen
Zelfs als het systeem geen gebruik maakt van persoonsgegevens die een basis voor discriminatie vormen, bestaat het gevaar dat andere, ogenschijnlijk neutrale informatie, verbanden aan het licht brengen die samenvallen met de gronden voor discriminatie. De reden hiervoor is dat machine learning-modellen vaak superieur zijn in het blootleggen van relaties, maar een beperkt vermogen hebben om onderscheid te maken tussen causaliteit en correlaties .
Uit onderzoek blijkt dat het nuttig kan zijn om de persoonsgegevens die rechtstreeks verband houden met de discriminatiegronden te bewaren, zodat we het systeem kunnen testen en kunnen nagaan of verschillende groepen mensen het slechter doen dan andere.
Een bijzondere uitdaging waarmee rekening moet worden gehouden tijdens het testen van het systeem, het bovengenoemde fenomeen, is samengestelde discriminatie.
Als het systeem wordt getest op discriminatie op groepsniveau dat er volledig boven ligt (zoals geslacht), kan discriminatie fijner worden gemaskeerd – dan kan het groepsniveau over het hoofd worden gezien. De combinaties van discriminatiegronden zijn als het ware eindeloos (bijvoorbeeld verschillende leeftijdsgroepen, geslacht, verschillende varianten van functionele beperkingen, verschillende etniciteiten).
Dit toont het belang aan van kennis van sociale omstandigheden en de aannames van verschillende groepen in de context waarin het systeem moet functioneren, om het systeem te kunnen testen op mogelijke zwakheden.
Actuele kwesties die besproken moeten worden
Voer het testen van het systeem uit:
- Hoe presteert het model ten opzichte van de succescriteria die in fase 1 zijn gedefinieerd? Als zodanig:-Hoe presteert het systeem in termen van fout-positieve/fout-negatieven voor verschillende groepen? — vergelijk de resultaten voor de verschillende groepen.-Zijn er gegevens beschikbaar om te kunnen controleren op discriminatie voor verschillende groepen?-Wie is verantwoordelijk voor het opvolgen van de prestaties van het model op deze punten?
- Hoe worden vertegenwoordigers van hen betrokken in de testfase?
Correlaties of causaliteit:
Documentachtergrond voor verbindingen
- Wat zijn de onderliggende redenen voor de voorspellingen die het systeem geeft?
- Onderzoek of door koppeling van gegevens persoonsgegevens kunnen worden afgeleid die aan discriminatiegronden kunnen worden gekoppeld.-Zo ja: wat is de reden hiervoor?-Overweeg het feitelijke doel, de noodzaak en de evenredigheid.
5. Implementatie
In deze fase gaat het erom hoe er rekening wordt gehouden met het gebruik van het systeem. In de fase wordt ervan uitgegaan dat het testen van het systeem (fase 4) bevredigende resultaten oplevert.
Relevante discriminatie-uitdagingen
Als uit het in kaart brengen van de vragen in de voorgaande fasen blijkt dat het systeem het risico met zich meebrengt dat het voor bepaalde groepen slechter gaat werken, of bepaalde groepen strenger behandelt dan andere, en dit in het systeem zelf niet kan worden aangepast, moet er onderzoek worden gedaan of er een mogelijkheid is om één alternatieve behandeling aan te bieden die de betreffende groepen een gelijke behandeling geeft. Als dat ML-systeem wordt geïmplementeerd, is het van cruciaal belang dat er toezicht is op hoe het systeem in de loop van de tijd presteert. Deze technologie is dynamisch en veranderingen op basis van de ervaringssystemen bepalen de tijd dat deze in gebruik wordt genomen. Daarom kan een niet-discriminerend model in de loop van de tijd discriminerende eigenschappen ontwikkelen.
Actuele kwesties die besproken moeten worden
De aanvulling op het model:
- Kunnen discriminerende berekeningen van het systeem worden gecompenseerd in het licht van relevante groepen mensen?
Controle :
- Hoe kan een echte menselijke verificatie van de beslissingen over individuele elementen van het model worden gegarandeerd?
- Hoe wordt de structurele controle met het systeem gewaarborgd? Als zodanig:- Controlemechanismen voor het model zorgen voor even nauwkeurige beslissingen voor alle groepen, en- Controlemechanismen om ervoor te zorgen dat het model bepaalde groepen niet systematisch strenger verwerkt.
Verzoek om informatie (innsyn) en communicatie :
- Voor wie moet kennis van het systeem en de toepassing ervan open en beschikbaar zijn? Breng in kaart welke informatie de verschillende groepen belanghebbenden nodig hebben om de vertrouwensmaatschappij te waarborgen, en welke richtlijnen daarin zijn vastgelegd hoe de informatie beschikbaar wordt gesteld.
- Hoe worden degenen die door het systeem worden getroffen, voor hun belangen behartigd? Als zodanig:-Noodzakelijk inzicht in hoe het model werkt?-Welke discriminatiebeoordelingen worden er uitgevoerd?-Zijn er echte oproepen?
Evaluatie:
- Definieer een evaluatiestrategie (continu of periodiek) en betrek bij voorkeur externe deskundigen en belangenorganisaties die betrokkenen kunnen vertegenwoordigen.
- Hoe zou het systeem hebben gewerkt met een alternatief model, rechtvaardigheidsdefinitie of algoritme?
- Moet het systeem op basis van de evaluatie verder worden ingezet, aangepast of beëindigd?
Speciale dank voor de ontwikkeling van de gids
De auteur dankt Inga Strümke (NTNU), Helga Brøgger (DNV), Robindra Prabhu (NAV), Iris Bore (NAV), Rita Gyland (NAV), Jacob Sjødin (NAV), professor Dag Elgesem (UiB) en Vera Sofie Borgen Skjetne (BufDir), die input heeft geleverd bij het ontwikkelen van deze gids.
Ik hoop dat je dit nuttig vond, en het brengt je op de hoogte van enkele van de ontwikkelingen die in Noorwegen gaande zijn op het gebied van AI-beleid en ethiek.
Dit is ook onderdeel van mijn persoonlijke project #1000daysofAI en je leest artikel 519. Ik schrijf 1000 dagen lang één nieuw artikel over of gerelateerd aan kunstmatige intelligentie. De eerste 500 dagen schreef ik elke dag een artikel, en nu van 500 tot 1000 schrijf ik in een ander tempo.
Kunstmatige intelligentie Ai-beleid Noorwegen Discriminatie Beleid
.avif)